


由于近年来淘宝的反爬措施逐渐完善,爬取难度变大,在爬取时必须要登录之后才能查看相关的商品信息,淘宝数据是通过动态加载的方式显示的,所以本文使用selenium模拟浏览器操作爬取商品页详情信息。
需要提取安装和selenuim和浏览器驱动chromedriver,由于chorme浏览器的自动更新,所以导致我的chrome浏览器版本和chromedriver版本不一致,所以使用了 chromedriver_path=r’C:ProgramFilesGoogleChromeApplicationchromedriver.exe’
browser = webdriver.Chrome(executable_path=chromedriver_path) 的方法成功加载了浏览器,在爬取淘宝美食的时候需要手动扫码等陆才可以保证爬取的顺利进行,最终成功爬取2733条记录。
在mongodb Compass看到以下数据: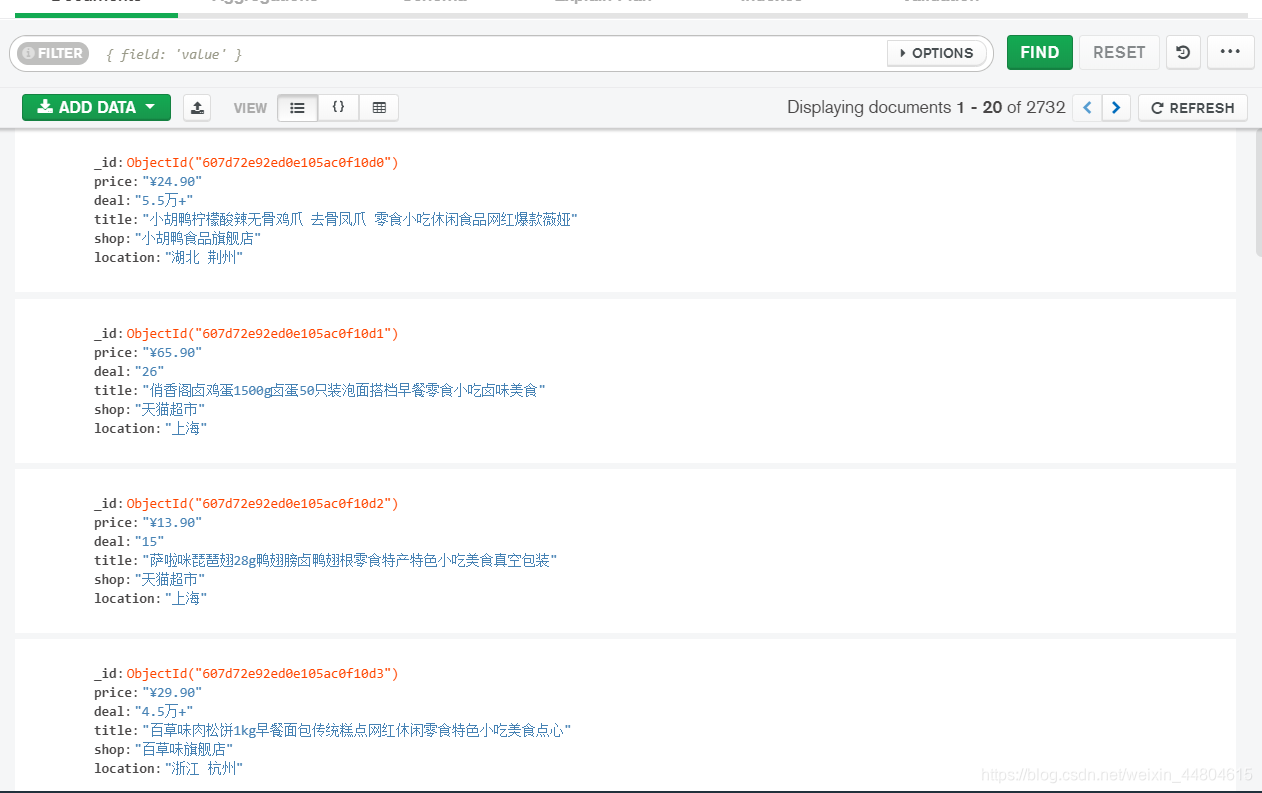 在mongodb的bin目录下使用命令:mongoexport -d taobao -c meishi.food -f _id,price,deal,title,shop,location–csv -o https://blog.csdn.net/weixin_44804615/article/details/D:/kesci.淘宝美食.csv 得到下表:
在mongodb的bin目录下使用命令:mongoexport -d taobao -c meishi.food -f _id,price,deal,title,shop,location–csv -o https://blog.csdn.net/weixin_44804615/article/details/D:/kesci.淘宝美食.csv 得到下表: 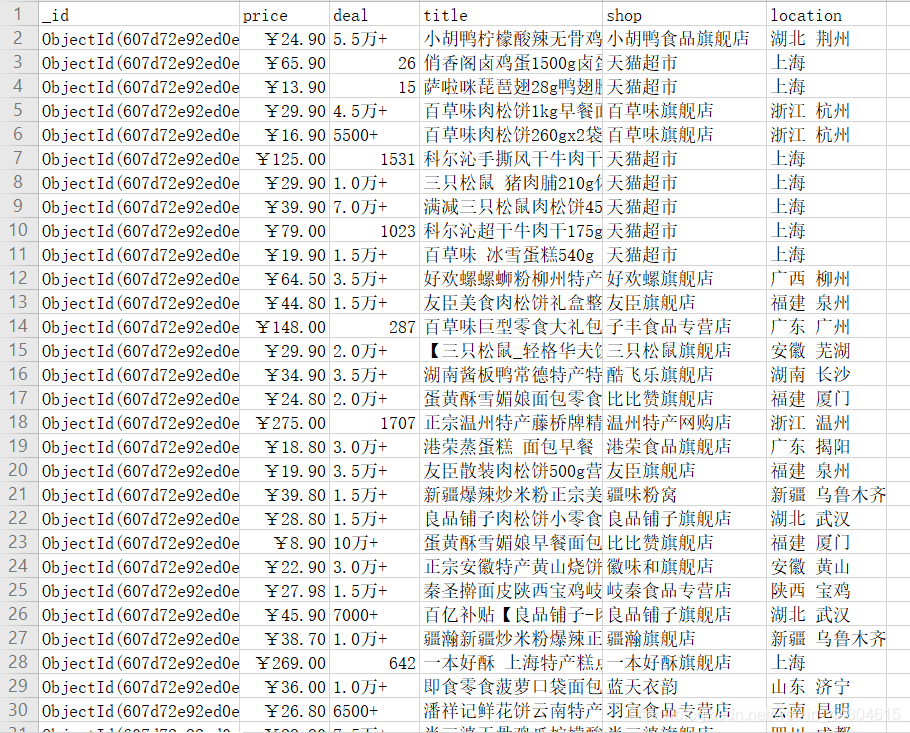 使用jupyter notebook读取数据
使用jupyter notebook读取数据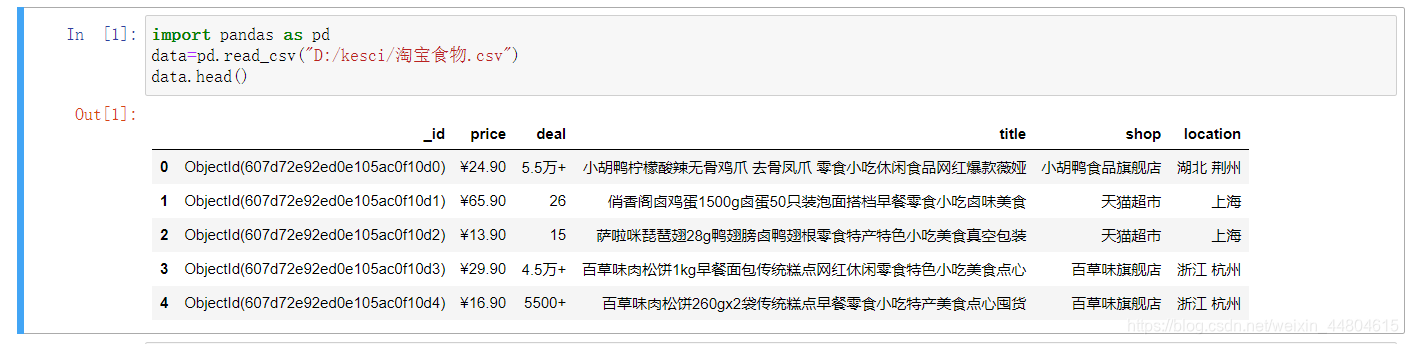 具体的清洗目标,这里以第一列数据为例:
具体的清洗目标,这里以第一列数据为例:
得到下图所示的数据:
下图是销售额在300000以上的店铺的销售和商品的平均单价: 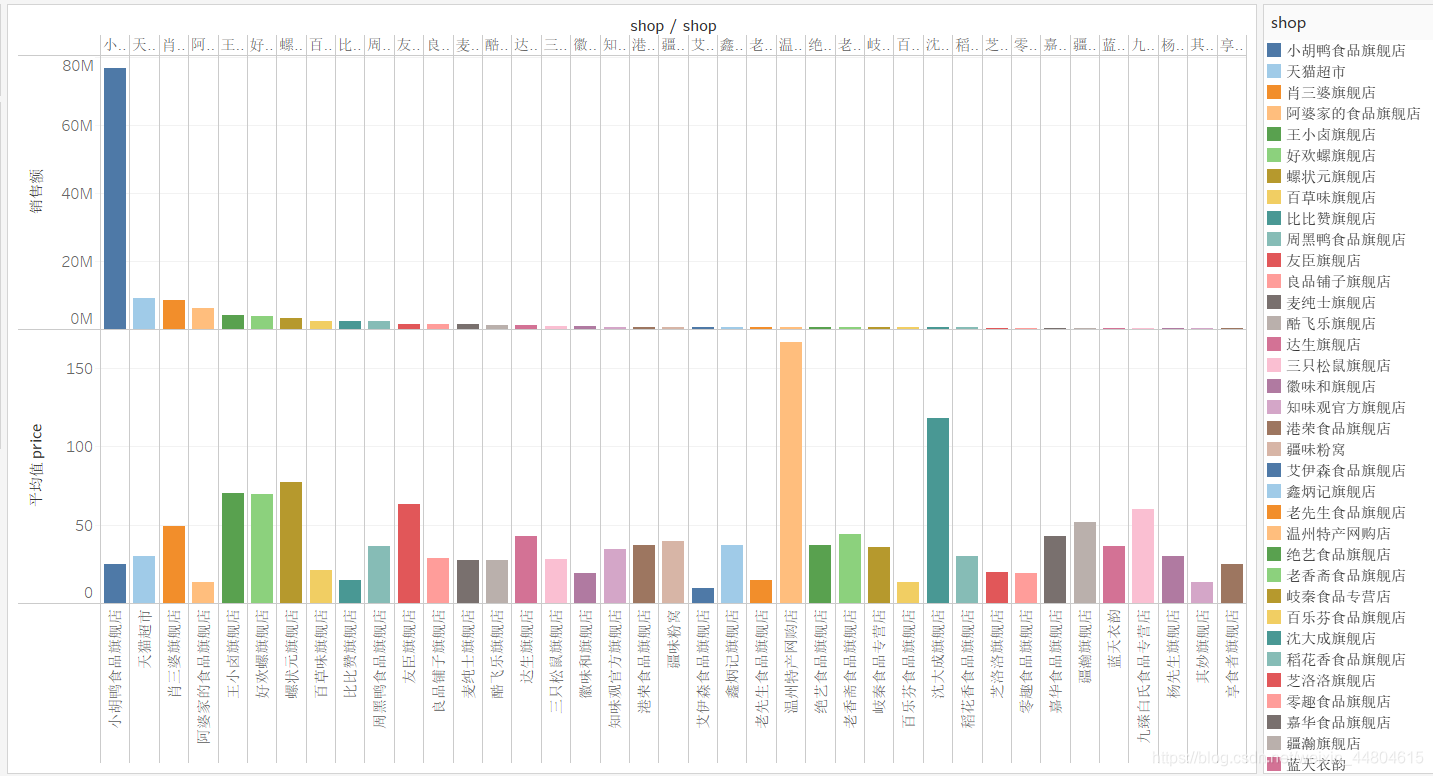 小胡鸭食品旗舰店销售额远超其他店铺,但其店铺内商品的平均单价处于偏低的水平,这表明大部分消费者面对商品单价低一点的商品表现出更强的兴趣,大多数消费者还是更能接收单次较低的消费。
小胡鸭食品旗舰店销售额远超其他店铺,但其店铺内商品的平均单价处于偏低的水平,这表明大部分消费者面对商品单价低一点的商品表现出更强的兴趣,大多数消费者还是更能接收单次较低的消费。
以下是各省的销售额排行: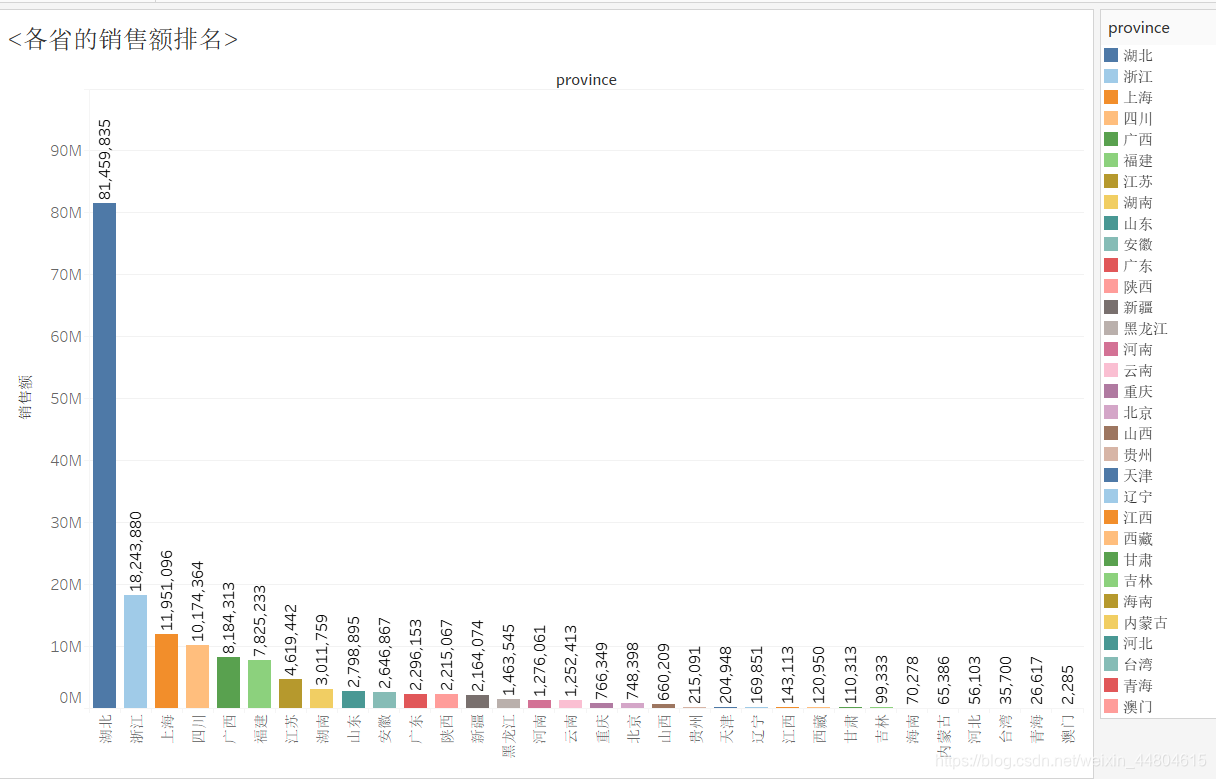 可以看出,湖北省基本是处于一家独大的地位,其销售额甚至是第二名浙江的四倍之多,甚至是其他省数十背,可见湖北人民对于淘宝上的美食非常感兴趣,可谓是‘吃货’最多的一个省了。 销售额超过三百万的省份有湖北、浙江、上海、四川、广西、福建、江苏、湖南,中国的淘宝美食销售基本就集中在这些地区。
可以看出,湖北省基本是处于一家独大的地位,其销售额甚至是第二名浙江的四倍之多,甚至是其他省数十背,可见湖北人民对于淘宝上的美食非常感兴趣,可谓是‘吃货’最多的一个省了。 销售额超过三百万的省份有湖北、浙江、上海、四川、广西、福建、江苏、湖南,中国的淘宝美食销售基本就集中在这些地区。
最后: 对各商品title进行文本分析,观察各种的美食关键词的出现频率,商品标题进行词频分析及可视化,使用jieba库以及一个中文常用停用词的文件用来排除一些无意义的常见词(例如:的、了之类的词)。